VOA News Special EnglishをトランススクリプトつきでPodcasting
ウノウラボで、http://labs.unoh.net/2006/09/post_44.htmlというエントリが紹介されてた。
英語の勉強法について書いてあるんだけど、その中で英語を聞くためのネタとしてVOA News Special Englishがオススメされていた。mp3で英語を聞きながら、聞き取れない箇所があればトランススクリプトで確認できて、なるほどよい感じ。
空き時間を利用してiPodで聞けないかな、と思って探してみると、VOA News Special EnglishはPodcastもあるみたい。だがしかし、Podcastにはトランススクリプトがついてない罠。なんとかならないかな?と考えていたら
「それPlaggerでできるよ」
という声が聞こえたので、さっそくやってみる。
EntryFullTextで全文を持ってきて、FindEnclosuresとHEADEnclosureMetadataでmp3ファイルをEnclosureにすればよさそう。mp3ファイルはそのまま使えるので、FetchEnclosureは使わないことにする。
voanews_com_specialenglish.yaml
author: mteramoto handle: http://www\.voanews\.com/.+/\d\d\d\d-\d\d-\d\d-.+\.cfm extract: <span class="datetime"><em>(.*?)</em></span>.*?</table>(.*?)</span> extract_capture: date body extract_date_format: %d %B %Y extract_date_timezone: UTC
てな感じでHandlerを書いてassets/plugins/Filter-EntryFullText/配下に配置。
voa_specialenglish.yaml
global:
timezone: Asia/Tokyo
plugins:
- module: Subscription::Config
config:
feed:
- http://www.voanews.com/specialenglish/customCF/RecentStoriesRSS.cfm?keyword=TopStories
- module: Filter::TruePermalink
- module: Filter::EntryFullText
- module: Filter::Rule
rule:
module: Deduped
- module: Filter::FindEnclosures
- module: Filter::HEADEnclosureMetadata
- module: Publish::Feed
config:
format: RSS
dir: /home/mteramoto/public_html/plagger/podcast/
filename: voa_specialenglish.xmlこれでvoa_specialenglish.xmlができるので、iTunesに読み込ませればOK。

ちゃんとPodcastとして読み込めてる。
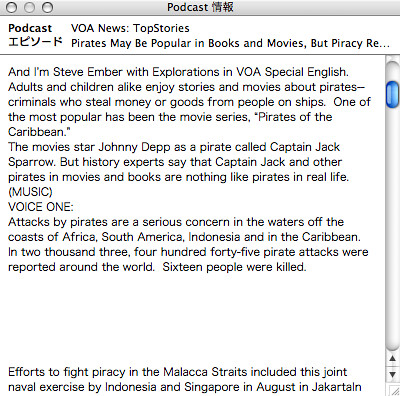
トランススクリプトもこのとおりばっちり。
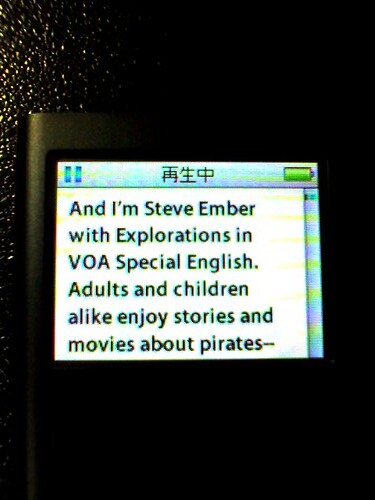
iPod nanoでもこのとおり、トランススクリプトが表示できる。Podcastの更新確認は1日1回にしてるから、cronで1日1回実行すればちょうどよさそう。
これで暇な時間にiPodで英語を聞きながら、分からないところがあればトランススクリプトを確認できるよ。
EntryFullTextとXPath
VOA News Special EnglishのPodCast化をXPathで微修正してみる - otsune's SnakeOil - subtechでid:otsuneさんがXPathを使ってステキに微修正してくれてるよ。
XPathというかXMLまわりは、今まで近寄りがたくて全然さわってないんだけど、なんだか面白そうだし少しさわってみよう。Filter::EntryFullTextならextract_xpath。内部でHTML-TreeBuilder-XPathを使ってるみたい。