XPathを使ってPlagger::Plugin::Filter::EntryFullTextのHandlerを書く
XPathとは - mteramotoの日記でXPathを覚えたので、さっそくEntryFullTextで使ってみる。
bodyのないFeedを探すと、ちょうどオルタナティブ・ブログが見つかったので、これをネタにしよう。
FireFoxのコンテキストメニュー「ページのソースを表示」を使ってソースをながめて、XPathを考える。
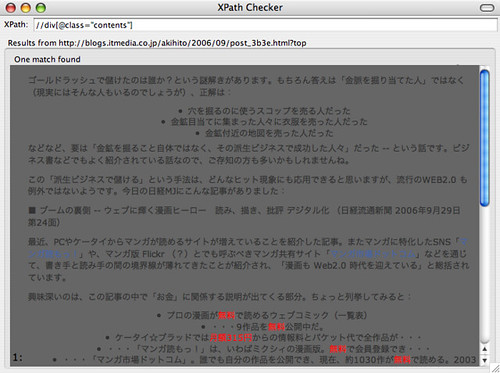
div[@class="contents"]がよさそう。XPath Checkerを使って、ちゃんと本文が取得できてることを確認。
Handlerはこんな感じかな。XPathがうまく使えると、すごく簡単に書けるのがうれしい。
author: mteramoto
handle: http://blogs\.itmedia\.co\.jp/.+/\d{4}/\d{2}/.+\.html
extract_xpath:
body: //div[@class="contents"]こんなconfig.yamlで実行してみた。
global:
timezone: Asia/Tokyo
log:
level: debug
plugins:
- module: Subscription::Config
config:
feed:
- http://blogs.itmedia.co.jp/index.rdf
- module: Filter::EntryFullText
- module: Publish::DebugいくつかExtract content failedが出てるな。たとえばhttp://blogs.itmedia.co.jp/goal/2006/10/happy_quest_b72a.htmlとか。むぅ、なんでだろ?
中身を見てみると、classがcontent_3ってなってたよ。すべてのブログを同じシステムで処理してるわけじゃないのね。仕方ないのでcontentsとcontent_3を両方取得して、extract_after_hookでどっちか取れた方をbodyに入れることにした。とりあえず動いたけど、どうもいけてない感が拭えないな。
author: mteramoto
handle: http://blogs\.itmedia\.co\.jp/.+/\d{4}/\d{2}/.+\.html
extract_xpath:
body1: //div[@class="contents"]
body2: //div[@class="content_3"]
extract_after_hook: |
$data->{body} = $data->{body1} || $data->{body2}
ところで、assets/plugins/Filter-EntryFullTextにあるyamlとかplはなんて名前で呼ぶんだろう?
Plagger::Plugin::Filter::EntryFullText(3)には
WRITING CUSTOM FULLTEXT HANDLER
(To be documented)って書いてあるから、今は勝手にHanderって呼ぶことにしてる。
XPathとLexical Structure
XPathでorを使えば、揺らいでいるWebページの切り抜きも簡単にok - otsune's SnakeOil - subtechでid:otsuneさんにアドバイスもらったよ、わーい。
- XPathにLexical Structureがあるなんて調べようともしなかった
- W3Cの文書にはちゃんと書いてあるから、目を通しておくこと>自分
- upgradeはbodyなしのFeedをupgrade、てな感覚なのかも
正規表現とgreedyなんて久々に聞いた気がする。最近、正規表現といえば
^(65535_)+(65534_)$
みたいなのしか使ってなかったから、すごい新鮮。
正規表現もちゃんと復習しておかないと、いつか痛い目に遭いそう。痛い目に遭って体で覚えていくのかもしれないけど。
とりあえず「詳説 正規表現」を引っ張り出して復習しよう。手元には第1版しかないけど、Perlの正規表現ならまだ対応してたはず。

- 作者: Jeffrey E.F. Friedl,田和勝
- 出版社/メーカー: オライリー・ジャパン
- 発売日: 2003/05/26
- メディア: 単行本
- 購入: 4人 クリック: 241回
- この商品を含むブログ (106件) を見る